我要投稿
我要投稿

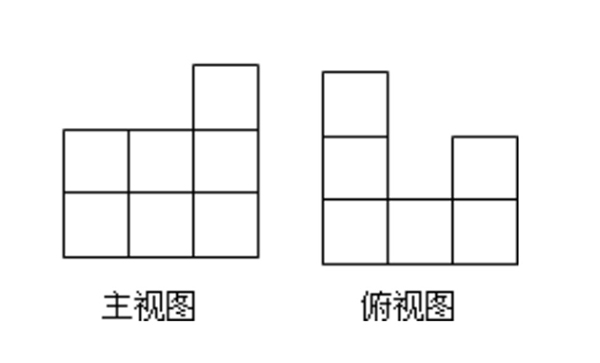
用小立方体搭一个几何体,使它的主视图和俯视图如图所示,这样的几何体最多需要多少个小立方体?最少需要多少个小立方体?
大家在学生时代可能都面对过这些涉及空间想象的几何题。从根本上,它们考验的是2D图像和3D场景间的转换能力。如今,人工智能也成功打破了这种“次元壁”。
一手打造史上最强围棋AI“阿尔法狗”的英国DeepMind团队,宣布其新开发的一种机器学习系统能在无人监督的情况下,从几个角度“观察”特定场景,然后生成该场景在其他角度上的样子。
相关论文发表在北京时间6月15日凌晨的世界顶级学术期刊《科学》上。

人工智能“看”到的2D几何体图片(左)和生成的3D几何体(右)
具体来说,这个名为生成查询网络(Generative Query Network, GQN)的系统分为两个部分:表示网络和生成网络。表示网络负责从2D样本图像中提取出一套用来表现场景的编码,而生成网络则可以输出该场景在新视角上的 可能图像。在这个过程中,网络也会考虑到不确定因素,比如场景图像存在部分模糊。
Seyed Mohammadali Eslami团队用电脑合成了虚拟的场景,其中包含不同物体和多个光源。他们用几张不同角度的场景图片训练计算机后,系统就能够生成该场景在任意角度上的图像。
甚至,当研究团队去除、增加场景中的物体,或者更改部分物体的形状或颜色后,系统依然能够得出相应的结果,并不需要人类向计算机解释“形状”和“颜色”的概念。研究团队认为,这表明人工智能并不是仅仅是在“拼凑”场景。
现在的机器学习方法需要大量经人类标注的数据进行训练,比如输入成千上万张猫的照片教会计算机识别出“猫”这个物种。而这种新的神经网络只需要少数几张2D 图片,无需人类标注。这为未来人工智能开辟了一条自主的新道路:人工智能可以通过自身携带的传感器观察并还原这个世界。

人工智能通过虚拟迷宫不同地点的图片,还原出相应场景。
比如,把这套系统应用在机械臂控制上的话,计算机只需要一个固定的摄像头记录2D图像,就能理解机械臂的运动情况。定位和控制机械臂所需采集的数据量就会大大减少。
文章链接:
S. M. Ali Eslami, et al, "Neural scene representation and rendering," Science 15 Jun 2018: Vol. 360, Issue 6394, pp. 1204-1210, DOI: 10.1126/science.aar6170
(本文来源:澎湃新闻;)
如若转载,请注明e科网。
如果你有好文章想发表or科研成果想展示推广,可以联系我们或免费注册拥有自己的主页
- 神经网络
- 人工智能